

Redis大Key分析和解決最佳實踐
神州信息
劉彬

1.
概述
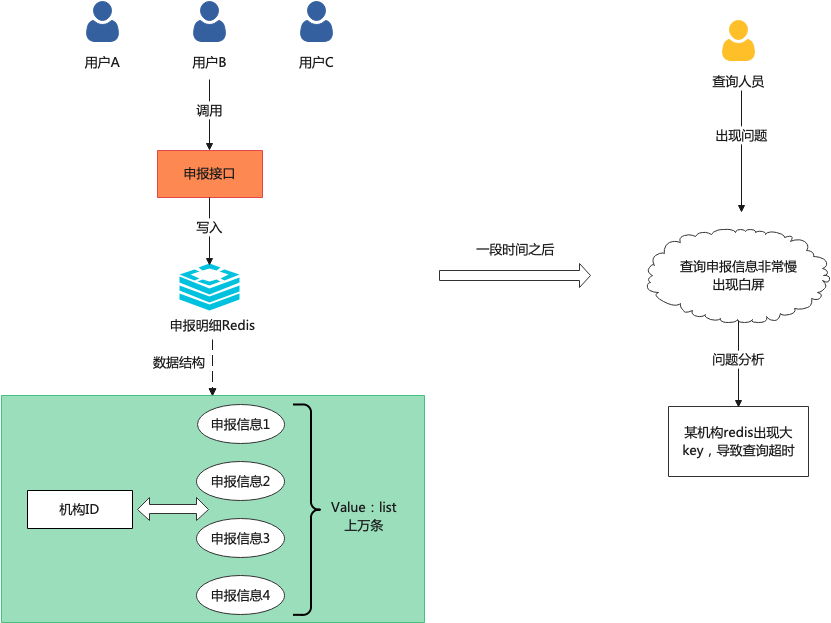
我們先假定有如下場景:某稅務(wù)局一線運維收到客戶反饋通知,說系統(tǒng)查詢某機構(gòu)對申報信息極為緩慢。于是開發(fā)人員找到一個出問題的機構(gòu)A,通過搜索日志系統(tǒng)找到系統(tǒng)操作Redis時間比較久,并且從日志系統(tǒng)搜到一些Redis 含詢超時的異常。最后我們定位到的原因如下:
在申報接口的時候系統(tǒng)通過Redis做了一個級存,記錄機構(gòu)的申報信息,Redis數(shù)據(jù)結(jié)構(gòu):key=機構(gòu)、IDvalue=申報列表,而Redis查詢發(fā)現(xiàn)多了許多大key,體現(xiàn)在一個機構(gòu)ID一天有上萬甚至幾十萬的申報信息。我們通常將此類問題稱為Redis大Key問題。
2.
Redis大Key基本概念及場景
所謂的大key問題是某個key對應(yīng)的value比較大,所以本質(zhì)上是大value問題,key往往是開發(fā)過程中可以自行設(shè)置,可以控制大小,value往往不受程序控制跟業(yè)務(wù)場景有關(guān)系,因此可能導(dǎo)致value較大。
2.1基本概念
在Redis中,大key指的是key對應(yīng)的value值所占的內(nèi)存空間比較大:
● value是string類型,大小建議控制在10kb以內(nèi)。
● valve是hash、list、set、zset等集合類型,元素個數(shù)建議不要超過 5000(或者1萬、幾萬)。上述的定義并不絕對,主要是根據(jù)value的大小和元索個數(shù)來確定,業(yè)務(wù)也可以很據(jù)自己的場景確定標淮。
2.2常見場景
大key的產(chǎn)生往往是業(yè)務(wù)方設(shè)計不合理,沒有預(yù)見vaule的動態(tài)增長問題。
通常有幾類此較經(jīng)典的場錄:
● 一直往value存放數(shù)據(jù),沒有刪除及過期機制。
● 數(shù)據(jù)沒有合理做分片,將大key變成以一個個小key。
3.
Redis大Key帶來的影響
● 客戶端超時阻塞。由于Redis單線程的特性,操作大key的通常比較耗時,也就意味著阻塞Redis可能性越大,這樣會造成容戶瑞阻塞或者引起故障切換,會出現(xiàn)各種Redis慢查詢。
● 內(nèi)存空間不均勻。集群模式在slot分片均勻情況下,會出現(xiàn)數(shù)據(jù)和查詢傾斜情況,部分有大key的Redis節(jié)點占用內(nèi)行多、QPS高。
● 引發(fā)網(wǎng)絡(luò)阻塞。每次獲取大key產(chǎn)生的網(wǎng)絡(luò)流量按大,如果一個key的大小為1MB每秒訪問量為1000,那么行秒會產(chǎn)生1000MB的流量。這對于普通千兆網(wǎng)卡的服務(wù)器說是災(zāi)難性的。
● 阻塞工作線程。執(zhí)行大key刪除時,在低版本Redis中可能阻塞線程。
4.
Redis大Key如何檢測
● 改寫Redis客戶端,在sdk中加入埋點,實時上報數(shù)據(jù)給Redis大key 檢測平臺、監(jiān)控告警。
● scan+debug object bigkey命令,循環(huán)遍歷Redis key序列化后的長度。debug object bigkey可能會比較慢,它存在阻塞Redis的可能,建議在從節(jié)點執(zhí)行該命令,官方不推薦。
● scan+memory usage。該命令是在Redis 4.0+以后提供的,可以循環(huán)遍歷統(tǒng)計計算每個鍵值的字節(jié)數(shù)。
● 通過python腳本迭代的scan key。對每次scan的內(nèi)容進行判斷是否為大key。
● Redis-cli --bigkeys。可以找到某個Redis 實例5種數(shù)據(jù)類型(string、hash、list、set、zset)的最大key。但如果Redis key 比較多,執(zhí)行該命令會比較慢,建議在從節(jié)點執(zhí)行該命令。
● rdbtools開源工具包。rdbtools是python寫的一個第三方開源工具,用來解析Redis快照文件,Redis實例上執(zhí)行bgsave,然后對dump出;來的rdb文件進行分析,找到其中的大key。
例如:rdb dump.rdb -c memory --byes 10240 -f Redis.csv
從dump.rdb 快照文件統(tǒng)計 (bgsave),將所有>10kb的key輸出到一個csv文件。
5.
Redis大Key如何刪除
如果對這類大key直接使用del命今進行刪除,會導(dǎo)致長時間阻塞,甚至崩潰,因為del命令在刪除集合類型數(shù)據(jù)時,時間復(fù)雜度為O(M),M是集合中元素的個數(shù)。Redis是單線程的,單個命令執(zhí)行時間過長就會阻塞其他命令,容易引起雪崩,穩(wěn)妥的建議如下:
主動刪除大Key
一、分批次漸近刪除
一般來說,對于string數(shù)據(jù)類型使用del命令不會產(chǎn)生阻塞。其它數(shù)據(jù)類型分批刪除,通過scan命令遍歷大key,每次取得少部分元素進行刪除,然后再獲取和刪除下一批元素.對Hash,Sorted Set, List. Set 分別處理、思路相同,先對key改名進行邏輯刪除,使客戶端無法使用原key,然后使用批量小步刪除。
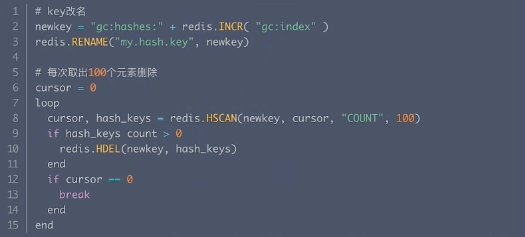
● 刪除大Hash
步驟:(1)key改名,相當于邏輯上刪除key,任何Redis命令都訪問不了該key。(2)小步多批次刪除。
偽代碼:
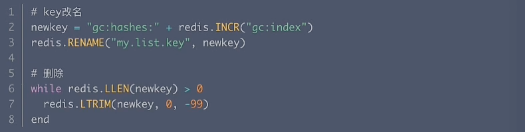
● 刪除大List
偽代碼:
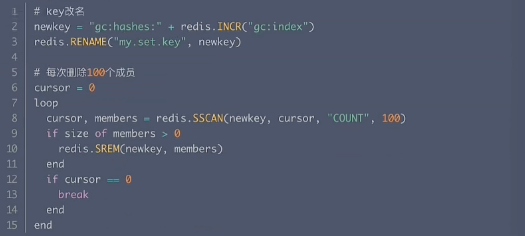
● 刪除大Set
偽代碼:
● 刪除大Sorted Set
偽代碼:
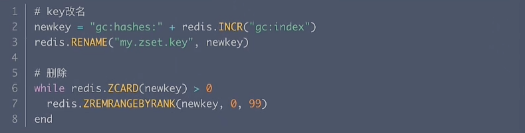
二、采用unlink+bigkey異步非阻塞刪除,這個命令是在Redis 4.0+提供的代替del命令,不會阻塞主線程。
被動刪除大Key
被動刪除是指利用Redis自身的key消除策略,配置lazyfree情性刪除。但是參數(shù)默認是關(guān)閉的。可配置如下參數(shù)開啟:

6.
Redis大Key如何設(shè)計與優(yōu)化
主要針對以下兩種經(jīng)典場景進行優(yōu)化:
單個key 存儲的 value 很大(超過 10kb)
1)從業(yè)務(wù)角度評估,value中只存儲有用的字段,盡量去掉無用的字段。
2)可以考點在應(yīng)用層先對value進行壓縮,比如采用LZ4/Snappy之類的壓縮算法,配合Redis客戶端序列化配置,可以無侵入完成value的壓縮。.
3)value設(shè)計的時候越小越好,關(guān)聯(lián)的數(shù)據(jù)分不同的key進行存儲。
4)大key分拆成幾個key-value,使用multiGet獲取值,這樣分拆的意義在于分拆單次操作的壓力.將操作壓力拼攤到多個Redis實例中,降低對單個Redis的IO影響。
5)對Redis集群進行擴容。
集合數(shù)據(jù)類型hash. list, set. sorted set等存儲過多的元素(超過5000個)
類似于場景一中的第一個做法,可以將這些元素分拆:
以hash為例,原先的正常存取流程是hget(hashKey,field) ;hset(hashkey,field,value)現(xiàn)在,我們可以分拆構(gòu)建一個新的 newHashkey,具體做法:固定一個桶的數(shù)量,比如10000每次存取的時候,先在本地計算field的hash值,取模10000,確定了該field落在哪個newHashkey上。

set、sorted、list也可以采用類似做法。


 ?京公網(wǎng)安備11010802043876
?京公網(wǎng)安備11010802043876